In a previous post I tried to provide some deep dive information about how the OpenStack with ACI OpFlex integration works when using the ML2 plugin. I covered quite a bit of ground, but I did not go into key features to enable external connectivity.
Now it is time to look at how we handle external connectivity and NAT when using the ACI Opflex integration for OpenStack.
Unfortunately, it has been a while since I started writing this post until I have finished it … here it goes.
NAT and Floating IP in OpenStack with ACI OpFlex integration
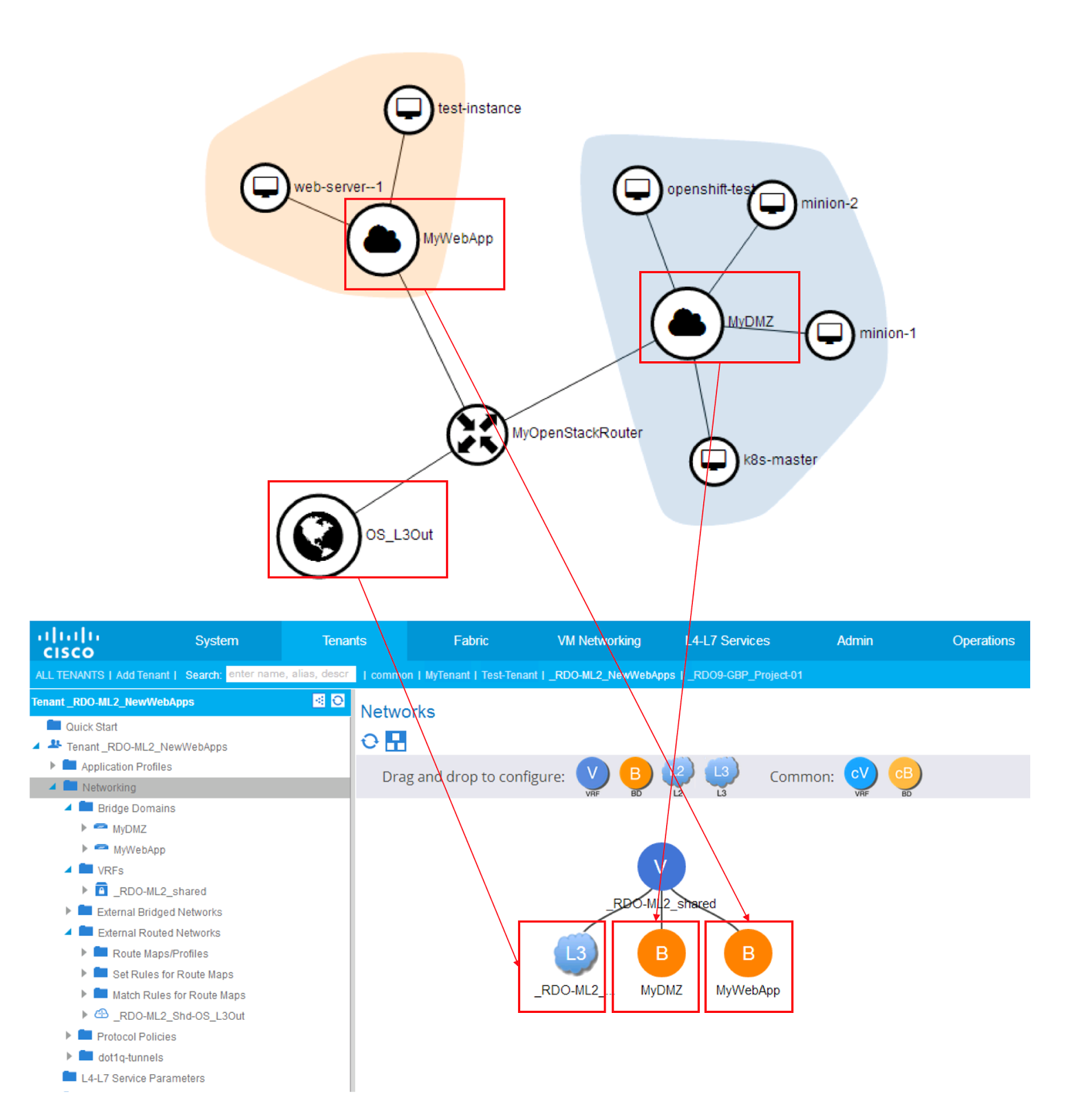
In OpenStack Opflex integration with ACI we will have by default an ACI tenant and VRF associated to each OpenStack Project which are configured when the OpenStack administrator creates the project.
Therefore, each of the projects will have its own dedicated address space. The instances within an OpenStack project may require connecting to endpoints in other projects and/or outside of the OpenStack cloud. This can be accomplished in a number of ways, however to communicate with endpoint that are not directly connected to the fabric, it is required to use L3Out interfaces.
L3Out interfaces can be mapped directly to neutron external networks. An OpenStack project can have its own L3Out interface that exists within the corresponding ACI tenant and VRF, or it can use a shared one from the ACI common tenant. This is what I will use in this example. When using a shared L3Out from the common tenant we assume that the OpenStack Project address space will be private, and that the Project will consume public routable address space that will exists in a VRF in the common tenant. Of course in this case, an instance that exists in the private VRF will require NAT to communicate on the public VRF.
The L3Out interface settings can be done directly on APIC by the fabric administrator, or they can be specified as part of the APIC OpenStack plugin configuration. The key pieces of configuration are inside /etc/neutron/plugins/ml2/ml2_conf_cisco_apic.ini.
One simple example:
[apic_external_network:OS_L3Out]
preexisting=True
enable_nat=True
external_epg=InternetAccess
host_pool_cidr=172.16.10.1/24
In this example, we are working with a pre-existing L3Out interface (i.e. we are not asking the APIC OpenStack plugin to create it for us) and we are enabling NAT. There are two types of NAT functions that we will use in this case:
- Source NAT or SNAT: this will enable an OpenStack tenant to have routable addresses that can be shared by many instances to access public resources. This is many to one NAT and assumes that the default route of the OpenStack router of the project is via the L3Out.
- Floating IP: this will enable an OpenStack tenant to have public routable addresses that can be assigned to instances. This is one to one NAT.
Source NAT Implementation
The SNAT address space is specified on /etc/neutron/plugins/ml2/ml2_conf_cisco_apic.ini.
On the config snippet from above, you see host_pool_cidr option. The prefix we configured there is used for SNAT. The APIC plugin will assign one IP address from that pool to each nova node in the cloud. Clearly the pool must be provisioned with enough IP addresses to accommodate for the number of nova compute nodes. With current software, all OpenStack tenants will share the SNAT pool.
To see this working, it is time for us to look at our APIC OpenStack VMM domain again. Let’s look at the endpoints that APIC reports as running on centos-01 (remember we have a small OpenStack “cloud” consisting of two nodes, centos-01 and centos-02).

I have highlighted an endpoint called snat|centos-01|OS_L3Out, it has IP address 172.16.10.2 and is connected to the network 'common|RDO-ML2|EXT-epg-OS|L3Out'. There is a similar entry for each hypervisor in the OpenStack cluster, for instance there is a snat|centos-02|OS_L3Out with IP address 172.16.10.3. These IP addresses are from host_pool_cidr=172.16.10.1/24 pool defined earlier in the plugin .ini configuration file.

In the lab setup, we are using a shared L3Out on the common tenant to provide an ingress/egress path for traffic external to the OpenStack cloud. The following diagram explains what is happening here looking at how our test-instance can access the external world using the hypervisor SNAT ip address:
In the diagram above, you can see the OpenStack tenant for the project in which test-instance is running on: NewWebApps. This has a corresponding ACI tenant and associated VRF.. Remember that in APIC the tenant name will be the OpenStack project name (NewWebApps) pre-pended by the VMM domain name (_RDO-ML2). As we have seen in the previous post, the test-instance with its private IP address 10.100.100.17 is connected to EPG MyWebApp.
When we created an external network for the OpenStack router of the tenant, a shadow-L3Out was created on the tenant and associated to a default contract that allows all traffic. The contract can allow all traffic because we must remember that in ML2 mode, security is provided by security groups, not by contracts (hint: you could still use contracts, but not provisioned through neutron unless using GBP mode).
At the same time, when we associated the NewWebApps router to the external L3Out, the APIC plugin has created a Bridge Domain under the default VRF in the common tenant, and it has created an application profile and an EPG for the public personality of the OpenStack instances. This is why on the diagram above I depict also the common tenant and default VRF, where I show the new BD: ESXt-bd-OS_L3Out. If you notice on the diagram, you can see the subnet 172.16.10.1/24 being created under the BD on the right. This subnet is automatically flagged to be announced via the OS_L3Out. You can see below the subnet 172.16.10.1/24 Advertised Externally. This is all configured by the APIC Plugin on behalf of neutron.

The routing table of the external router connected to the L3Out is learning this subnet via OSPF (or the routing protocol of your choice) as we can see the routing table below, where we see the 172.16.10.0/24 subnet and we do not see internal subnets like 10.100.100.0/24.

On the diagrams above, we will have seen an endpoint named snat|centos-01|OS_L3Out. This is the SNAT endpoint on that particular hypervisor. On each hypervisor the SNAT interface will be configured with a dedicated namespace having the unique address assigned by the plugin for SNAT from the pool assigned for this purpose.
To verify this is all working well you would start by listing the namespaces on the hypervisor (ip netns list) and then checking the ip address for the corresponding namespace, as well as the port on the Open vSwitch. The following shows all this related back to the VMM domain information centos-02, where we see also the SNAT endpoint on the EPG EXT-epg-OS3LOut:

Now, when our test-instance sends traffic towards a private address that matches a subnet known to the tenant’s VRF, it will be switched or routed on the tenant’s VRF and IP space. However, if it tries reaching an external IP address then it will hit a default route that points to the L3Out interface and in this case, the source IP address will be NAT’ed with the SNAT address of the hypervisor. For an instance running on centos-02 this will be 172.16.10.3. See the below diagram to see the flow of connectivity where we have test-instance accessing the external Ubuntu-desktop-os with IP address 192.168.200.1:

So the traffic for all OpenStack instances running on centos-02 that require external access - assuming that the security groups allow it - will be coming out from the nova node sourced with the SNAT address and into EPG EXT-epg-OS_L3Out on the public IP space with the IP address of the hypervisor they run on.
This allows connectivity to any resource accessible via the common tenant. Of course this is valid for external endpoints, as depicted above, but also for anything connected to the common tenant like shared services, etc. If you do VRF leaking from common tenant to other non-OpenStack tenants, this would also allow connectivity to other tenant resources.
To verify that SNAT is working we can test it quickly by starting a ping from our test-instance towards 192.168.200.1 (an external host).

The ping is successful and we can see it by using tcpdump on the hypervisor on the tap interface at the corresponding to the instance, which we found on the previous blog:

But on the capture above we can see packets are sourced by 10.100.100.17! That is the private address our test-instance …
If we check the packets received by our external host:

We can see packets coming in from 172.16.10.3. Also remember that our external router has no route towards 10.100.100.0/24 subnet. The packets are being NAT’ed on OVS.
Floating IP
SNAT is great for allowing external access for OpenStack Virtual Machines. All that we need is have an OpenStack router configured with an external network associated to a shared L3Out, and security group configuration to allow external connectivity to happen. This is useful if an OpenStack VM needs to access external resources, like a Linux repository, or a Docker registry for instance.
But what happens if I need an instance to be accessible by external endpoints?
One alternative is to use routable addresses for your instance as already mentioned. This is perfectly possible and you can route for each tenant with its own L3Out. But typically not all instances require to be accessible and you don’t want to use public address space for every instance in an OpenStack project.
So you will have a smaller pool of IP Addresses that you will route externally and share for those IP. You assign those IP to instances using Floating IP. This is equivalent to AWS Elastic IP address concept.
The subnet for Floating IP is defined for external networks in neutron, if we list the networks again (neutron net-list) we see for OS_L3Out the associated subnet is 172.16.20.0/24:

And not by coincidence that is the other subnet we see on the Bridge Domain EXT-bd-OS_L3Out on the common tenant that we are using for our external routable addresses. As soon as you associate a Floating IP subnet to an OpenStack tenant external network, the OpenStack APIC plugin will create that subnet under that BD. This subnet is also announced automatically to our external router as we can see below with a snapshot of the external router routing table:

For SNAT, all OpenStack projects will share the same pool. However for Floating IP each project can have its own subnet. And they can all share the same NAT EPG, or each tenant may have its own NAT EPG. For instance, if you would like different Projects to communicate to one another, you may want to keep them on the same NAT EPG. Otherwise, you can have per-tenant NAT EPG for Floating IP and then enable communicate between them if required using ACI contracts.
Now we will look at our test-tenant instance, it has no Floating IP associated:

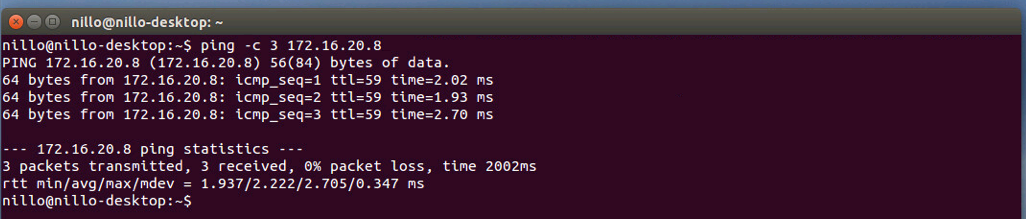
Using a standard neutron call or using Horizon, we will now associate a Floating IP for this instance. We will use IP Address 172.16.20.8. But before we do that, let’s review the OpenFlow tables for this IP Address:
There are no entries.
And now we associate the floating IP using Horizon, then we will review again the table:

And we can see now the FIP associated and the OVS openflow tables populated to perform NAT:

And if we remember, from our test above we left our ping running from the test-instance towards the external host, so there’s a ping going from 10.100.100.17 towards 192.168.200.1. If we go to the external host again and run a tcpdump we no longer see the packets coming from the SNAT address:

Instead, we can see that packets are now coming from the Floating IP 172.16.20.8. And now our external host can also ping that IP address:
Part of the interest in the ACI OpenStack integration is to facilitate operations of the cloud from the fabric perspective. For instance, we can also use the APIC EP Tracker feature to find this IP address and we can see it is attached recently only to the external EPG for NAT EXT-epg-OS_L3Out:

This way, for a fabric administrator, this isn't just an IP address, but instead you can see that this particular address corresponds to an OpenStack Floating IP and quickly find where it connects on the fabric, learn how it attaches to the fabric (which port, tunnel encapsulation ...). Also, now that we know which EPG this endpoint is connected on, we can learn more about it, like the node where it runs and more:

We can see this ‘test-instance’ connected on that EPG, and we can see it is running on centos-02 under RDO-ML2 domain, connected via VXLAN. This is usual information correlating the overlay, the underlay and the information of the virtualisation controller that you get with APIC and other virtualisation solutions, but in this case via neutron/nova server.
Summary
OpenStack is a good option for organisations that want to implement a Private Cloud, particularly if they have good in-house Linux skills. Choosing ACI as the fabric to support any Private Cloud makes a lot of sense, and in the case of OpenStack you can then leverage at no extra cost the OpFlex integration.
The ACI OpenStack OpFlex integration leverages APIC in a great way, combining its capabilities to manage the physical fabric assets as well as the virtual switch. It works with standard Open vSwitch. Through this integration organisations can benefit from distributed routing and switching, distributed NAT/SNAT and distributed DHCP and Metadata services, as well as from the fabric hardware capabilities to connect with endpoints to OpenStack.